Java框架面试题

面试题
Spring Bean作用域区别
- 使用scope指定bean的作用于
| 属性 | 介绍 |
|---|---|
| singleton | 默认值,当IOC容器一创建就会创建bean的实例, 是单例的,每次得到的都是同一个 |
| propotype | 原型的,当IOC容器创建时不创建bean, 每次调用getBean方法时再实例化bean,而且不是同一个 |
| request | 在web环境中使用,每次HTTP请求实例化一个bean |
| session | 在web环境中使用,在一个HTTP Session会话中共享一个bean |
Spring常用数据事物传播属性和事务隔离级别
事物的属性
Propagation:用来设置事物的传播行为
- 传播行为:一个方法运行在一个开启事物的方法中,当前方法是使用原来的事务还是开启一个新的事物
- Propagation.REQUIRED:默认值,使用原来的事物
- Propagation.REQUIRES_NEW:将原来的事物挂起,使用新的事物
事物的隔离级别
Isolation:用来设置事物的隔离级别
- Isolation.REPEATABLE_READ:可重复读,MySql的默认隔离级别
- Isolation.READ_COMMITTED:读已提交,Oracle的默认隔离级是
Spring的生命周期
- 实例化,初始init,接收请求service,销毁destroy
- 实例化一个Bean,等同于new
- 按照Spring上下文对实例化的Bean进行配置,也就是IOC注入
- 如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String)方法,此处传递的就是Spring配置文件中Bean的id值
- 如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(setBeanFactory(BeanFactory))传递的是Spring工厂自身(可以用这个方式来获取其它Bean,只需在Spring配置文件中配置一个普通的Bean就可以)
- 如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文(同样这个方式也可以实现步骤4的内容,但比4更好,因为ApplicationContext是BeanFactory的子接口,有更多的实现方法)
- 如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术
- 如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法
- 如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法
- 当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法
- 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法
@Autowired和@Resource区别
- @Autowired注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false
- @Resource注解是按名称装配,称可以通过@Resource的name属性指定
- @Resources按名字,是JDK的,@Autowired按类型,是Spring的
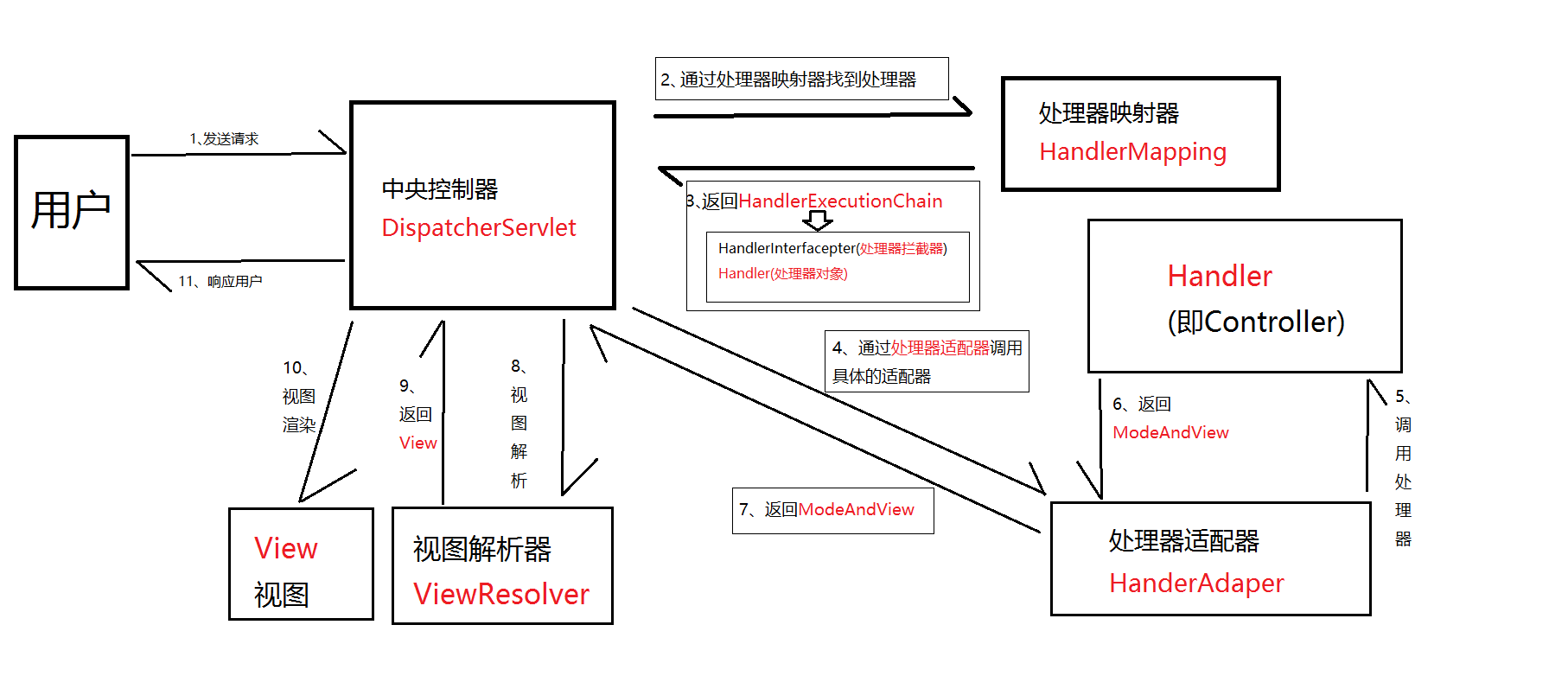
SpringMVC的工作流程
MyBatis数据库字段名和属性名不一致解决
写sql语句的时候起别名
1
select user_name userName from user;在MyBatis的全局配置文件中开启驼峰命名
1
2
3
4
5<settings>
<!-- 开启驼峰命名 -->
<!-- 将userName映射为user_name -->
<setting name="mapUnderscoreToCamelCase" value="true"></setting>
</settings>在Mapper文件中使用resultMap自定义映射规则
1
2
3<resultMap type="top.jtxyh.User" name="myMap">
<id column="user_name" property="userName"/>
</resultMap>
MyBatis的一级缓存和二级缓存
- Mybatis的一级缓存首先去缓存中查询结果集,作用域是一个SqlSession,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。
- Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句,value为从查询出来映射生成的java对象
- Mybatis的二级缓存即查询缓存,作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据,二级缓存是可以跨SqlSession的
Git分支相关命令
创建分支
- git branch <分支名>
- 查看分支:git branch -v
切换分支
- git checkout <分支名>
- 一步完成创建和切换分支:git checkout -b <分支名>
合并分支
- 先切换到主干:git checkout master
- git merge <分支名>
删除分支
- 先切换到主干:git checkout master
- git branch -D <分支名>
工作流应用

Redis持久化有几种类型和区别
RDB
- 在指定的时间间隔内将内存中的数据集快照写入磁盘,类似于Snapshot快照,恢复数据的时候是直接将快照直接读到内存中
- 执行流程:Redis会单独创建一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,RDB比AOF更高效,但最后一次持久化后的数据可能会丢失
- 优点:节省磁盘空间,恢复速度快
- 缺点:数据庞大时消耗性能
AOF
- 以日志的形式记录每个写操作,将Redis执行过的指令记录下来,追加到文件不改写文件,Redis重启后就根据日志的内容将写指令从前到后执行一次恢复数据
- 优点:备份机制稳健,丢失数据概率低
- 缺点:比RDB更占用磁盘空间,恢复备份速度慢,存在个别Bug
Redis在项目中的使用场景
| 数据类型 | 使用场景 |
|---|---|
| String | 比如封锁某个IP地址时可以使用 |
| Hash | 存储用户信息的时候 |
| List | 实现最新消息的排行,可以模拟消息队列 |
| Set | 可以自动排重,求共同交集的时候使用 |
| Zset | 进行排序的时候可以使用 |
MySQL索引
索引介绍
- 索引是数据结构
- 索引是帮助MySQL高效获取数据的数据结构
- 索引是以索引文件的形式存储在磁盘上
那些情况需要索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该建立索引
- 查询中于其他表关联的字段,外键关系建立索引
- 组合索引比单键索引效率更高
- 查询中排序的字段
- 查询中统计或者分组的字段
那些情况不需要索引
- 表记录太少
- 经常增删改的表或者字段
- Where条件里用不到的字段
- 过滤性不好的不适合建索引
单点登录的实现过程
介绍
- 单点登录:一处登录多处使用
- 前提:单点登录多使用在分布式系统中
实现

购物车实现过程
用户和购物车的关系
- 一个用户必须对应一个购物车
- 单点登录操作在购物车之前
购物车操作
- 添加购物车
- 用户未登录将数据添加到Redis或者Cookie中
- 用户登录后用Hash存储到Redis和数据库中
- 展示购物车
- 未登录的时候直接从Redis或Cookie中展示数据
- 登录后,必须从数据库和Redis和Cookie中展示购物车中的数据
消息队列
弊端
- 容易出现消息的不确定性
- 可以使用延迟队列和轮询技术解决



相关文章

